来自西班牙萨拉曼卡大学的研究者们日前于International Journal of Molecular Sciences (IJMS)上发表了他们关于免疫肽组实验的技术工作,评估了如何通过优化实验以提高免疫肽的鉴定结果和分析效果。论文标题:Crucial Parameters for Immunopeptidome Characterization: A Systematic Evaluation;链接:https://doi.org/10.3390/ijms25179564
研究者们主要评估的实验技术包括:
-细胞裂解方法:不同的细胞裂解策略影响蛋白质和肽段的提取效率。CHAPS裂解液在本工作中被证明有最好的提取效率。
-IP策略:免疫沉淀方法对肽段回收效率是最重要的步骤。研究评估了两种不同的亲和基质对肽段识别数量的影响,并表明基于CNBr-activated Sepharose 4B beads偶联抗体的回收策略更高效(如下图)。注:本工作的分析仪器为timsTOF Pro.
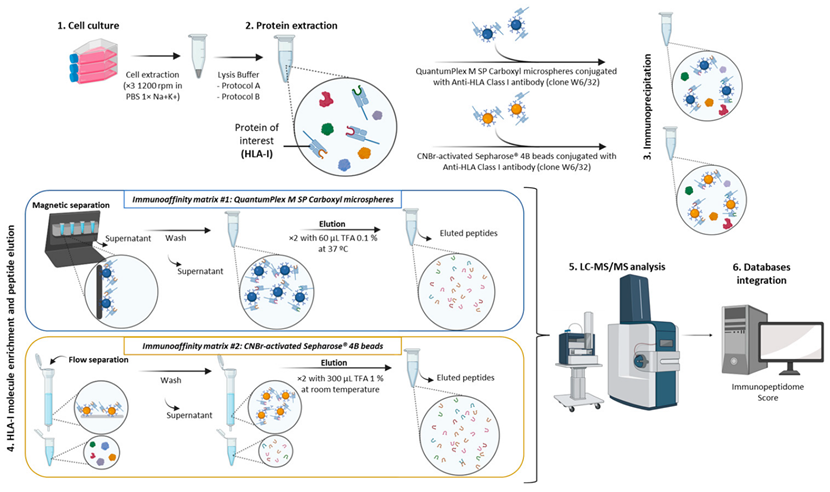
-论文中还对使用数据库搜索或de novo从头算方式获得实验结果的分析方式进行了评估。
本工作的第二个贡献在于提出了一个“免疫肽组评分”:根据肽段的长度、与MHC分子的结合能力以及免疫原性等三个因素(如下图),以期对实验效果进行定量。打分高的多肽更有具有分析的价值;含有更多打分高的多肽的免疫肽组实验流程效果更好。
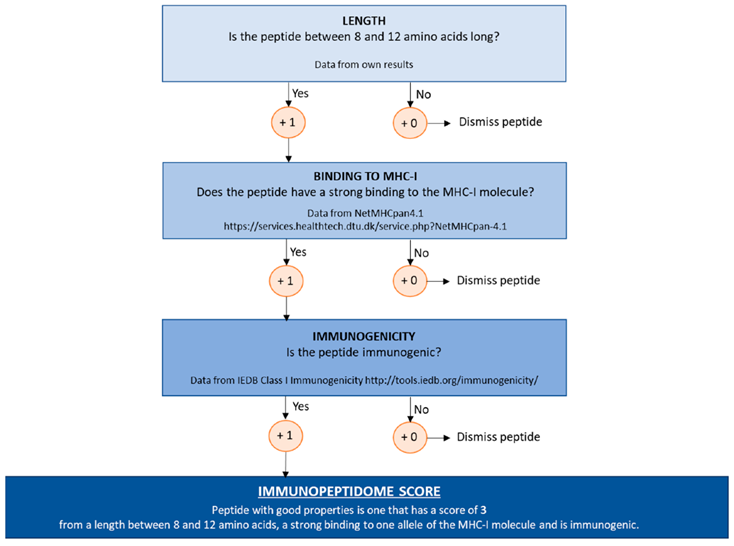
总之,本工作为免疫肽组的实验评估提供了一个系统性的分析框架,并提出了“免疫肽组评分”概念,在小规模实验中可以起到参考作用。虽然是发表在风评soso的IJMS上,但这篇技术论文的干货很足;附件中也给出了详尽的protocol和对应的实验数据。