English Title: Something Old in MS + AI = A New Company
来自初创公司Tesorai和马普所的科学家们日前在BioRxiv上公开了他们的研究论文:Tesorai Search: Large pretrained model boosts identifications in mass spectrometry proteomics without the need for Percolator。MaxQuant的开发者jurgon Cox是论文作者之一;Tesorai联合创始人Peter Cimermancic是论文通讯。链接 https://doi.org/10.1101/2024.08.19.606805
这项研究介绍了一种名为Tesorai的、用于质谱蛋白质组学分析的大数据训练模型。基于文中评述,传统质谱蛋白质组学中的数据库匹配算法通常会漏掉多达75%的谱图识别;而基于机器学习方法(Percolator等)对匹配结果进行再次评估(专业名词叫statistical validation)虽然能提高识别度、但也可能导致错误发现率(FDR)估算不准确。Tesorai训练了超过1亿对真实的肽谱(peptide-spectrum match);对得到的模型“赋能”传统的数据库匹配。通过这种方法,蛋白质组学的分析不再需要虚拟肽(decoys)这种本身极具争议的设定;分析结果相较Prosit等传统方法对普通胰酶处理样本提升30%、对免疫肽组样本提升5%、对泛蛋白质(metaproteomics)样本提升50%。此外,该模型还通过利用云计算提升了处理速度、可以在数小时完成数百个分析。如上文所述,Tesorai已经spin off出了一家科技公司:tesorai.com;用户通过直接网络上传质谱数据就可以获得分析结果(当然是要收费的;按文件个数收费)。在AI已经渗透到蛋白质组学分析每一步的当下(推荐论文: Artificial intelligence for proteomics and biomarker discovery. Cell Systems 12 (8), 759-770 (2021)),研究者们们居然还能在①依赖AI生成库(AlphaPeptDeep, Prosit等)和②不依赖库而使用AI从头算(PEAKS等)中间找到并开辟出利用AI替换掉decoys的小众赛道,令笔者击节叹赏。读者朋友们,你们还能找到尚有可为的something old吗?
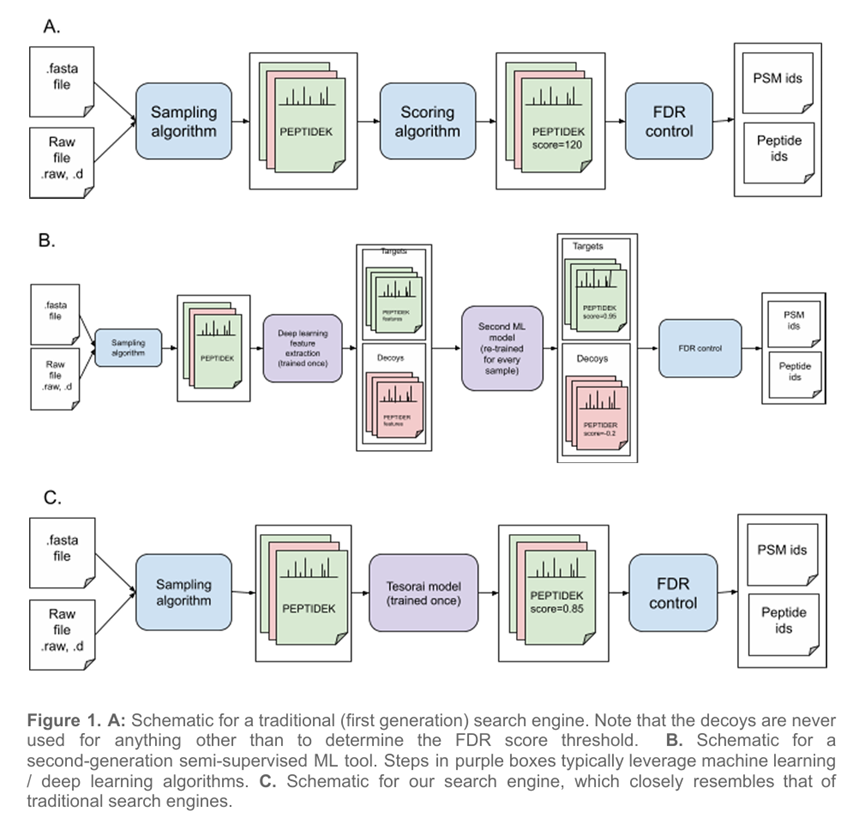
质谱数据搜索引擎的示意图。注意:图C才对应本文使用的搜索引擎示意。